In short, my four reasons for using GIT are:
- Because it is distributed, it allows people to work on projects without having an account
- It is really fast
- All revisions of every file _are_ always locally available for you to inspect
- Easy branching
The one thing I adore most about GIT, is that it is a distributed system. Not by itself ofcourse, but this gives you incredible freedom (from a software developers perspective). To explain what is so great about this, I'll illustrate how development used to go with CVS and Subversion and similar systems.
Lets assume you are not a member of the project you want to work on. Then you'd have to check out their code from their software repository, make some changes and then -as you want to get it back and integrated- make a patch and send it to the projects mailinglist.
This doesn't sound that bad. Until you actually start working this way. The problem is that you do not have any versioning system for your own changes. You are working on a read-only repository and have no way to check in small changes.
So, what do some developers do (as I did)? They set up a local repository and import the external projects code. They have write access to that local repository, so they can start make changes while having their changes versioned.
The problem with this approach is that you will most likely want to keep synchronized with the official project sourcecode. So now and then you'd have to try and create a patch and solve lots of conflicts.
So, you'd say, okay, lets synchronise more often, so that the patches keep nice and small, and the conflicts would be easy to fix. Ofcourse, but the problem is that there is no automated way to do this, so it would involve a lot of work.
GIT makes this trivial. With GIT you'd make a clone of the projects repository. Within this clone you can do as you please, as it is your local repository. Now and then (very often) you just pull in the changes from the main project repository and you solve the conflicts that might occur.
How difficult is it to set such an environment up?
git-clone http://your.favorite/project.git
That's it.
Now, you enter the newly created project directory and start hacking and committing your new changes with:
git-commit -a
After a while you want to resynchronize with the main project repository, so you do a:
git-pull
GIT will get all the new code from the main repository, and will try to automatically merge it. If it fails, it will mark the code with the familiar ">>>" markers, as in both CVS and Subversion. After solving the conflicts, you commit again.
Or, you can keep one branch in your own repository identical to the main repository, and create a separate branch for your own development:
git branch mywork
git checkout mywork
Do whatever stuff you want to do in this branch and commits as much as you want to. Afterward you can pull from the main (called master) branch to your branch:
git pull . master
So, this command means that you want GIT to pull in the changes from the master branch into your current branch (being the one you were hacking in).
Speed
Another great benefit of GIT is that it's fast, really fast. I once did a comparison of GIT versus CVS, Subversion, TLA and Bazaar (and possibly others, can't recall). I used the Linux kernel source tree as contents for my revision control systems, and imported the 2.6.0 kernel. Then proceeded committing the 2.6.1 diff, 2.6.2, etc. After going up until 2.6.something, I then made a normalsized patch, and did a commit, GIT was blazingly fast while the other were unworkably slow. Recently Jo Vermeulen did a similar test and published the results on his blog. His tests focus on Bzr being comparable to GIT performancewise.
Full history at your fingertips
The entire sourcecode of the FFmpeg project, with every revision of every file included, fits into 9MiB using GIT. This means that you can have the entire development history of the project on your local harddrive. As it can be stored easily on your harddrive, it is very fast to access, as no calls need to use network connections at all.
Easy branching
Another nice thing about GIT is the ease with which one can create branches. And, in contrary with f.e. SVN and CVS, you feel comfortable to create branches _all the time_. Why? Because
you can delete them whenever you want, and no traces will remain. So, after the following commands, the repository will be the same as before the commands:
git-branch profile
git-branch h264
git-branch -D h264
git-branch -D profile
So, I typically create branches for whatever patch I am about to create. In fact, I actually just start working on something, and if it starts out being something worth keeping, I create a branch and commit the just created codechanges in that newly created branch.
Diffs between branches are easy too:
git diff profile..h264
Pulling in changes from a different branch into the current one:
git pull . somebugfix
Using GIT
If you want to use GIT, you'll better enjoy using the commandline, as the most powerful features are available through the commandline. There are some GUI's available too, mostly for inspecting codechanges.
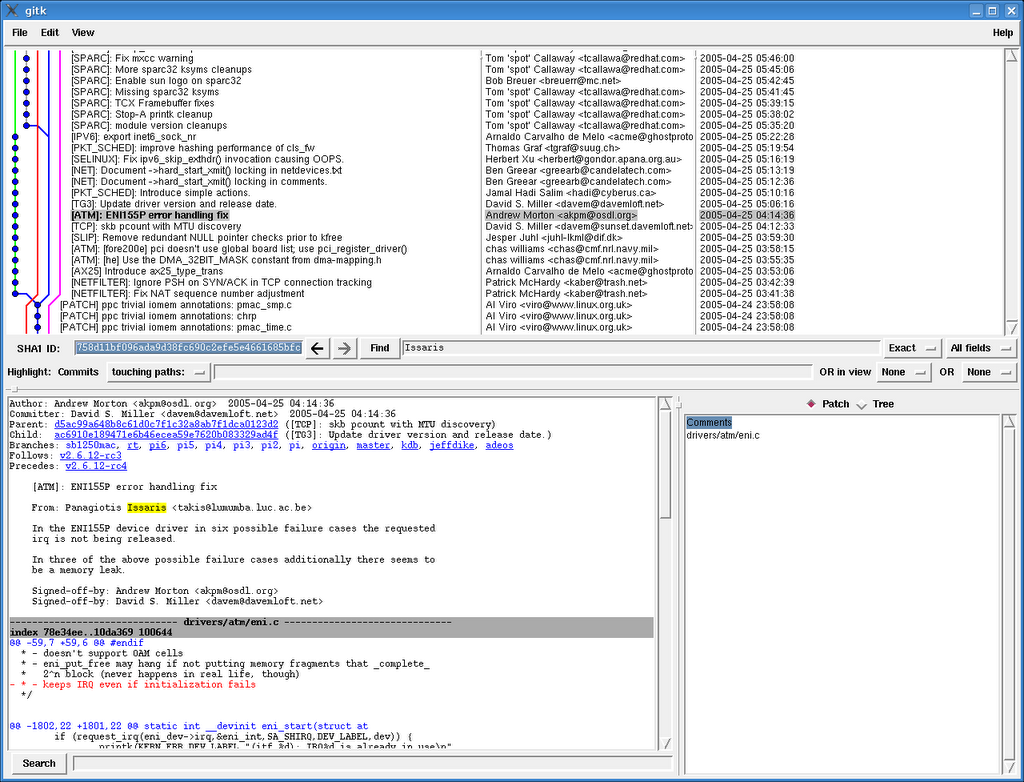
There's a GUI included, called gitk:
Such as QGit:

And, for the Curses lovers, tig:
Update: As Uoti Urpala commented on the FFmpeg mailinglist, and as I should have mentioned above, the distributed nature of GIT isn't unique. There are a lot of other distributed revision control systems: Mercurial, Bazaar, Bitkeeper, SVK, TLA/Arch, darcs, ... In fact, I tested a few of those a long time ago, and noticed that performance was suboptimal for some (TLA/Arch and at the time Bazaar - but as I said that was a long time ago) and some seemed a bit immature, others were closed-source and commercial software. So, for me the choice was rather obvious. Recently, I have been told Bazaar has made excellent progress performancewise, so that might be an interesting candidate too. I never really tried Mercurial, although I did have the impression that it might have all the advantages GIT has...
Update2: Jo Vermeulen pointed me to this mail on the Cairo mailinglist where similar advantages concerning GIT are being illustrated.

3 opmerkingen:
Actually the new version of Bazaar is written as "bzr" :-)
There have indeed been quite some performance improvements recently. I am not sure if bzr can already outperform git, but it might in the future, who knows? Maybe it's time for me to redo the performance test again :-)
I completely agree with your arguments about distributed revision control systems. This is the way to go in my opinion.
There are currently a couple of distributed VCS's. I mostly prefer the user-friendly ones. I enjoyed darcs for a long time. Unfortunately darcs is too slow for large source trees. The bzr developers tried to achieve the same user-friendliness as darcs, together with the advanced features of git and the likes. As you already know, bzr is therefore my personal favorite :-) The advantage of both bzr and git is that they have received extensive testing. git is being used by the kernel developers, while the guys at Canonical use bzr for Ubuntu's Launchpad.
Whatever the outcome of this battle will be, I believe the idea of distributed revision control is going to improve the situation :-)
Actually the new version of Bazaar is written as "bzr" :-)
There have indeed been quite some performance improvements recently. I am not sure if bzr can already outperform git,
At least Bazaar-NG writing speed has come up to par with git - now that it is only three characters long ;-)
[...]
Maybe it's time for me to redo the performance test again :-)
Eagerly awaiting it! =)
There is one which had gone out of my focus for a while, which seemed to be a few steps ahead of GIT when I looked at it (last year June or so). Aurelien Jacobs brought Mercurialto my attention again on the FFmpeg mailinglist. It is apparantly not only being used by Xen (I had heard about that) but also by Alsa, V4L, OpenSolaris and apparently the FreeBSD people are considering it too.
That's a nice tutorial.
I was looking for something like this for ages.
I am planning to use a versioning system for my own projects but I was not sure to use. I tried CVS a later I switched to SVN mainly because I can use it through SSH (svn+ssh) which is a must have for me. Is it possible to use GIT through SSH as well ?
Een reactie posten